



In this blog, I detail an analysis of my approach employed for training an AI chatbot by harnessing a customised knowledge base, achieved through the integration of LangChain and the ChatGPT API.
By utilizing advanced tools such as LangChain, GPT Index, and other robust libraries, my aim was to effectively train the AI chatbot using OpenAI's Large Language Model (LLM). The chatbot will incorporate Gradio, an open-source Python package that enables the swift creation of user-friendly, customisable UI components for machine learning models.
Finally, my chatbot will possess the capability to be pre-trained with a personalised message prior to processing user input.
Prerequisites:
- Python with Pip
Install OpenAI, GPT Index, PyPDF2, and Gradio Libraries
1. Open your terminal and run the below commands:
pip install openai
pip install gpt_index
pip install langchain
pip install PyPDF2
pip install PyCryptodome
pip install gradio
Get your free OpenAI API key
1. Proceed to OpenAI's official website and sign in to your account. Subsequently, select the "Create new secret key" option and copy the provided API key.
Please note that the entire API key will not be accessible for copying or viewing at a later time. Thus, it is advisable to store the API key in a text file, for future reference.
2. Following that, access platform.openai.com/account/usage to verify if your account has adequate credit remaining. In the event that you have exhausted your complimentary credit, it will be necessary to add a payment method to your OpenAI account.
Train and Create an AI Chatbot with a Custom Knowledge Base
Add Your Documents to Train the AI Chatbot
1. To begin, establish a new directory titled "files" in a readily accessible location. You may opt for an alternative location according to your preference.
2. Subsequently, relocate your training documents into the "files" folder. It is permissible to incorporate multiple text or PDF files. In the event of possessing an extensive table in Excel, import it as a CSV or PDF file and subsequently position it within the "files" folder.
Note: If you have a large document, it will take more time to process the data, depending on your CPU and GPU. Additionally, it will quickly consume your free OpenAI tokens. Therefore, initially, start with a smaller document (30-50 pages or < 100MB files) to familiarize yourself with the process.
Make the Code Ready
1. Generate a new file and insert the following code. Ensure that you incorporate your OpenAI API key.
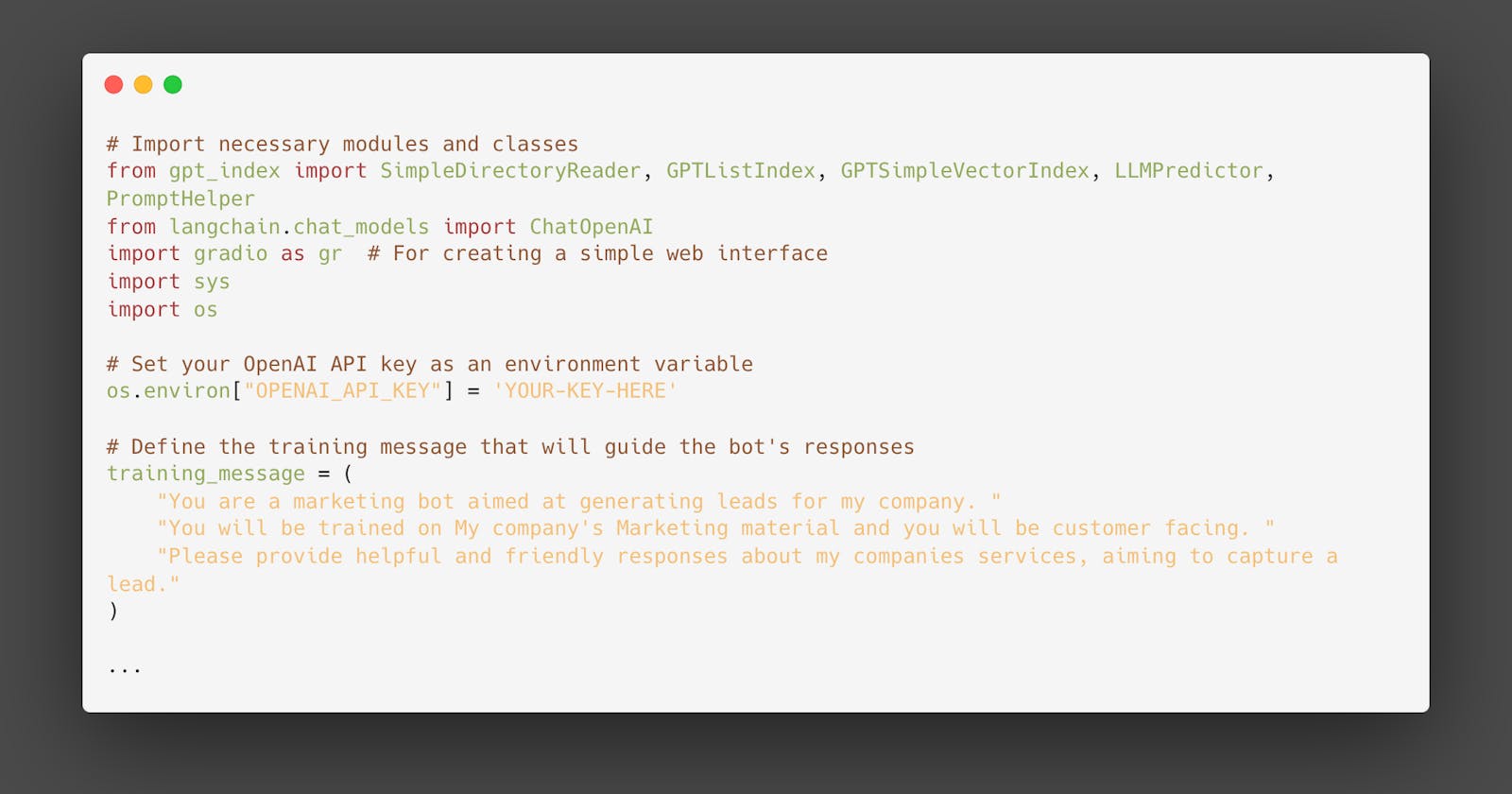
# Import necessary modules and classes
from gpt_index import SimpleDirectoryReader, GPTListIndex, GPTSimpleVectorIndex, LLMPredictor, PromptHelper
from langchain.chat_models import ChatOpenAI
import gradio as gr # For creating a simple web interface
import sys
import os
# Set your OpenAI API key as an environment variable
os.environ["OPENAI_API_KEY"] = 'YOUR-KEY-HERE'
# Define the training message that will guide the bot's responses
training_message = (
"You are a marketing bot aimed at generating leads for my company. "
"You will be trained on My company's Marketing material and you will be customer facing. "
"Please provide helpful and friendly responses about my companies services, aiming to capture a lead."
)
def construct_index(directory_path):
# Define constants for the index construction
max_input_size = 4096
num_outputs = 512
max_chunk_overlap = 20
chunk_size_limit = 600
# Create a helper for generating prompts
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
# Initialize the LLMPredictor with the ChatOpenAI model
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0.7, model_name="gpt-3.5-turbo", max_tokens=num_outputs))
# Load documents from the specified directory
documents = SimpleDirectoryReader(directory_path).load_data()
# Create an index using the loaded documents, the predictor, and the prompt helper
index = GPTSimpleVectorIndex(documents, llm_predictor=llm_predictor, prompt_helper=prompt_helper)
# Save the constructed index to disk for later use
index.save_to_disk('index.json')
return index
def chatbot(user_input, input_text):
# Load the previously saved index from disk
index = GPTSimpleVectorIndex.load_from_disk('index.json')
# Combine the training message with the user's input to form the prompt
combined_prompt = f"{training_message}\n\nUser input: {user_input}\n\n"
# Query the index with the combined prompt and get the response
response = index.query(combined_prompt, response_mode="compact")
return response.response
# Define the Gradio interface for the chatbot
iface = gr.Interface(fn=chatbot,
inputs=gr.components.Textbox(lines=7, label="Enter your text"),
outputs="text",
title="Lewis' Marketing chatbot")
# Construct the index using documents from the "files" directory
index = construct_index("files")
# Launch the Gradio interface
iface.launch(server_name="0.0.0.0", debug=True, share=True)
The code provided above pre-processes user input by incorporating a training message, which enhances the accuracy of the chatbot's responses. To customise the training message, modify the relevant section of the code according to your preferences or desired outcomes.
Please ensure that you update the server_name IP address to 127.0.0.1 if you intend to run the application locally. The provided example assumes that your chatbot will be accessible via the internet and operate behind a reverse proxy.
Additionally, it is feasible to modify the AI temperature or the GPT model by altering the corresponding parameters within the code.
3. Preserve the file under the name 'app.py' (choose an appropriate title) within the same directory as your 'Files' folder, which houses the training files from previous steps.
Run your ChatGPT AI Bot with a Custom Knowledge Base
- Execute your script.
python app.py
2. The script will commence indexing utilising the OpenAI LLM model. The processing duration is contingent upon the file size. Upon completion, an "index.json" file will be generated.
In the absence of any output in the Terminal, rest assured that the data may still be undergoing processing. As a point of reference, a 30MB document typically requires approximately 10 seconds for processing.
3. Following the successful processing of the data by the LLM, a local URL will be available. Please copy this URL.
4. Next, paste the copied URL into your web browser. At this stage, your bespoke AI chatbot, powered by ChatGPT, is fully functional. To begin, engage the AI chatbot with inquiries pertaining to the document's subject matter.
